Optimizing Test-Time Compute for LLMs: A Meta-Reinforcement Learning Approach with Cumulative Regret Minimization


Enhancing the reasoning abilities of LLMs by optimizing test-time compute is a critical research challenge. Current approaches primarily rely on fine-tuning models with search traces or RL using binary outcome rewards. However, these methods may not fully exploit test-time compute efficiently. Recent research suggests that increasing test-time computing can improve reasoning by generating longer solution traces and incorporating structured steps such as reflection, planning, and algorithmic search. Key challenges remain whether LLMs allocate computational resources effectively based on task complexity and discover solutions to more difficult problems when given a larger test-time compute budget. Addressing these is crucial for improving efficiency and generalization in LLM reasoning.
Recent advancements in scaling test-time compute have explored training separate verifiers for selection-based methods like best-of-N or beam search, which can sometimes be more effective than increasing data or model size. However, fine-tuning on unfamiliar search traces may lead to memorization rather than genuine reasoning improvements. RL-based approaches have demonstrated promise in generating chain-of-thought reasoning, enabling models to introspect, plan, and refine their outputs. However, increasing reasoning length does not always correlate with higher accuracy, as models may generate unnecessarily long sequences without meaningful progress. To address this, recent efforts have incorporated structured reward mechanisms and length penalties to encourage efficient reasoning, ensuring that models focus on producing informative, concise solutions rather than excessive computation.
Researchers from Carnegie Mellon University & Hugging Face investigate optimizing test-time compute for LLMs by refining how models allocate computational resources during reasoning. Instead of relying solely on outcome-reward RL, they introduce a fine-tuning approach that balances exploration and exploitation, ensuring steady progress toward correct answers. Their method incorporates a dense reward bonus to quantify progress, improving efficiency. Evaluations on mathematical benchmarks demonstrate that this approach significantly outperforms existing methods, enhancing both accuracy and token efficiency. Their findings also suggest that optimizing for progress minimizes computational regret while improving solution discovery without sacrificing accuracy.
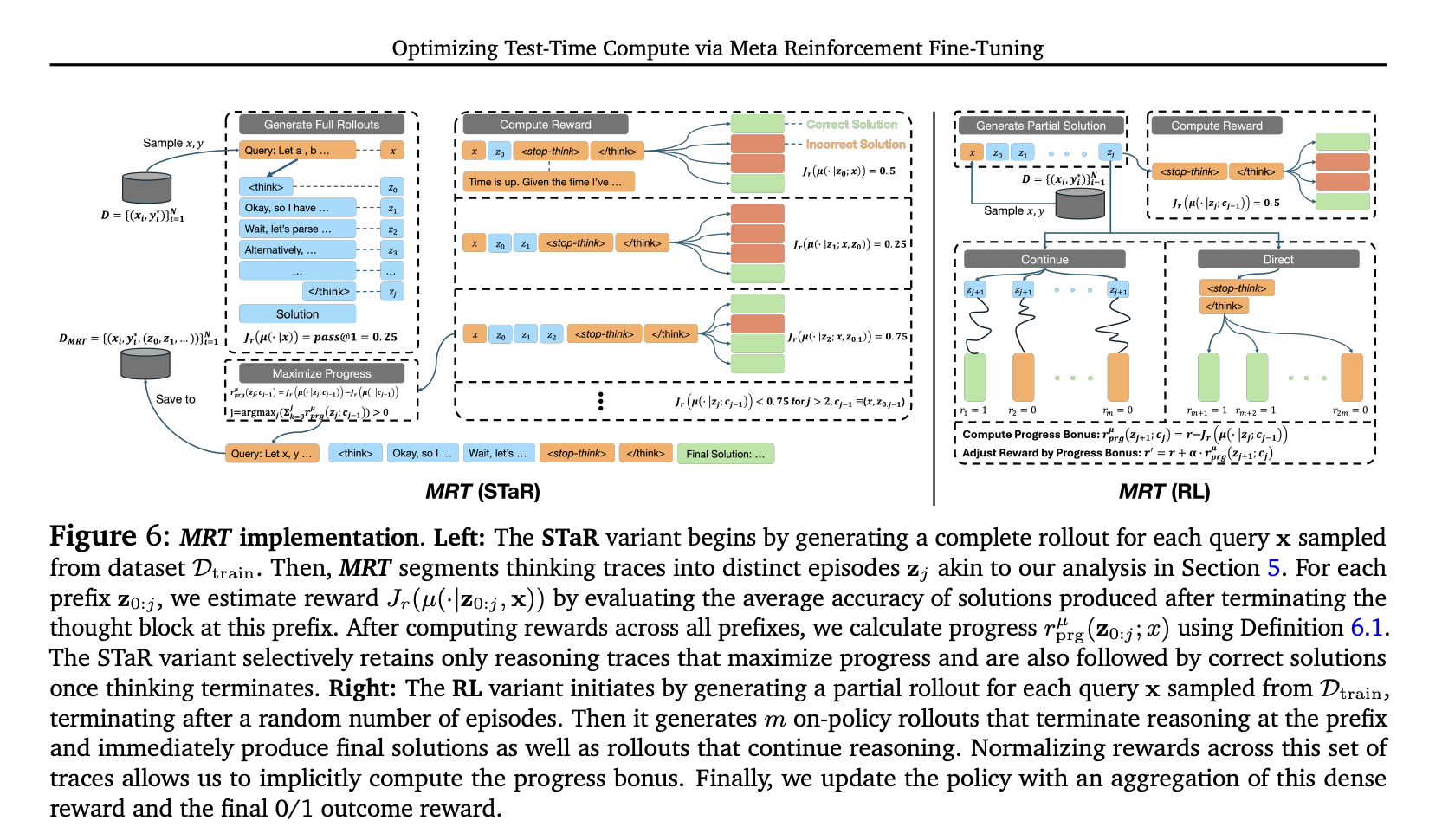
The problem of optimizing test-time compute is framed as a meta reinforcement learning (meta RL) challenge. The goal is to maximize an LLM’s performance within a given test-time token budget by balancing exploration and exploitation. Instead of solely optimizing for outcomes, the proposed Meta Reinforcement Fine-Tuning (MRT) approach minimizes cumulative regret by rewarding progress across sequential episodes. This budget-agnostic strategy allows LLMs to make steady progress regardless of training constraints. By incorporating a reward bonus based on incremental improvements, MRT ensures efficient test-time compute usage, enhancing adaptability and response accuracy within deployment constraints.
The study evaluates the effectiveness of MRT in optimizing test-time computation, with a focus on achieving high accuracy while maintaining computational efficiency. The study presents key findings, compares MRT’s efficiency with prior methods, and conducts ablation experiments on token budget and progress. MRT consistently outperforms baseline models and outcome-reward RL (GRPO), achieving state-of-the-art results in its size category. It also improves out-of-distribution robustness and delivers larger performance gains with weaker models. Furthermore, MRT significantly enhances token efficiency, requiring fewer tokens for comparable accuracy. Additional experiments highlight its effectiveness in backtracking search and linearized evaluations.
In conclusion, the study reframes optimizing test-time compute as a meta-reinforcement learning (RL) problem, introducing cumulative regret as a key metric. State-of-the-art outcome-reward RL models fail to minimize regret, often struggling with novel queries within a token budget. This limitation arises from training solely with outcome rewards, which lack the granularity to guide stepwise progress. To address this, MRT is proposed, incorporating a dense reward bonus that encourages incremental improvement. MRT enhances test-time compute efficiency, achieving 2-3x better performance and 1.5x greater token efficiency in mathematical reasoning compared to outcome-reward RL, though several open questions remain.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.